
RL vs next-token-prediction: why should it be a dichotomy?
Inspired from how humans master a new language.

Over the past few days/months, I came across many blog posts that are really enlightening:
Yiding Jiang – “The Era of Exploration”
Shunyu Yao – “The Second Half”
Roughly summarized, all these works are saying that pretraining on internet data using next-token-prediction objective sets up a good prior, and we are at the stage of scaling up RL by changing the environment and turning compute into data through exploration.
I can’t help but notice the underlying tension of RL vs next-token-prediction as learning paradigm. Aka i.e., you should apply them in a sequential fashion, but not at the same time in an interplay fashion within the same training stage.
While many of the times, we draw parallels of them to human learning (like how Ilya saying learning next-token-prediction gives rise to world model using detective story as analogy, and how RL is being thought of as like humans learning through trials and errors), it’s weird that they are not in blended fashion.
Because at least for language learning, blending both enables mastery of a new language.
tldr of my post
When we learn languages naturally, we're constantly doing both at the same time:
Immersion (like SFT): We absorb patterns, vocabulary, and structures by listening and reading.
Interactive practice (like RL): We try speaking, get feedback, adjust our usage.
Instead of "next-token-prediction → RL," perhaps we should be exploring ways for “next-token-prediction × RL” where we not only scale up both paradigms, but we also scale up the interplays between them so we can simultaneously maintain the benefits of continuous learning from passive observation while also actively explore and incorporate feedback.
on “Dreaming Spanish” curriculum
Have you tried using Duolingo to learn a new language? ARC creator François Chollet said that “it's completely ineffective at teaching languages but it's quite entertaining”. That is true in my experience. Duolingo starts off by forcing you to memorize word pairing––what does this reminds you of? Rule book / feature engineering aka the old school machine-translation or ML systems that cannot scale.
On the other hand, comprehensible input is a language learning method, rooted in Stephen Krashen's theory of language acquisition, where you simply expose yourself to conversations and being conscious about figuring out the message behind the words/sentences despite not knowing what those language units individually mean. The key is to scale up immersion in content you can at least comprehend a bit.
Aka, Just. Listen/Read (Absorb). A. Lot.
Dreaming Spanish curriculum uses this strategy and is extremely successful at helping a super-beginner build the foundation for eventually becoming fluent in Spanish.
Why do people point to Dreaming spanish so much?
A: You don’t need to be taking notes, and you shouldn’t be looking at subtitles. Don’t try and consciously translate, just try and follow what they’re talking about. It’s supposed to be teaching you Spanish the same way you learned your first language as a baby, and babies don’t understand anything at first. ––source
Notice how this is similar to next token prediction?
You simply absorb how one word leads to another without understanding the individual meaning of the word. At some point (after around 150 hours of accumulated input), you will start to get what a person is saying within a certain topic.1 You don’t need any form of reward signals–––you just simply absorb how one word follows the other.
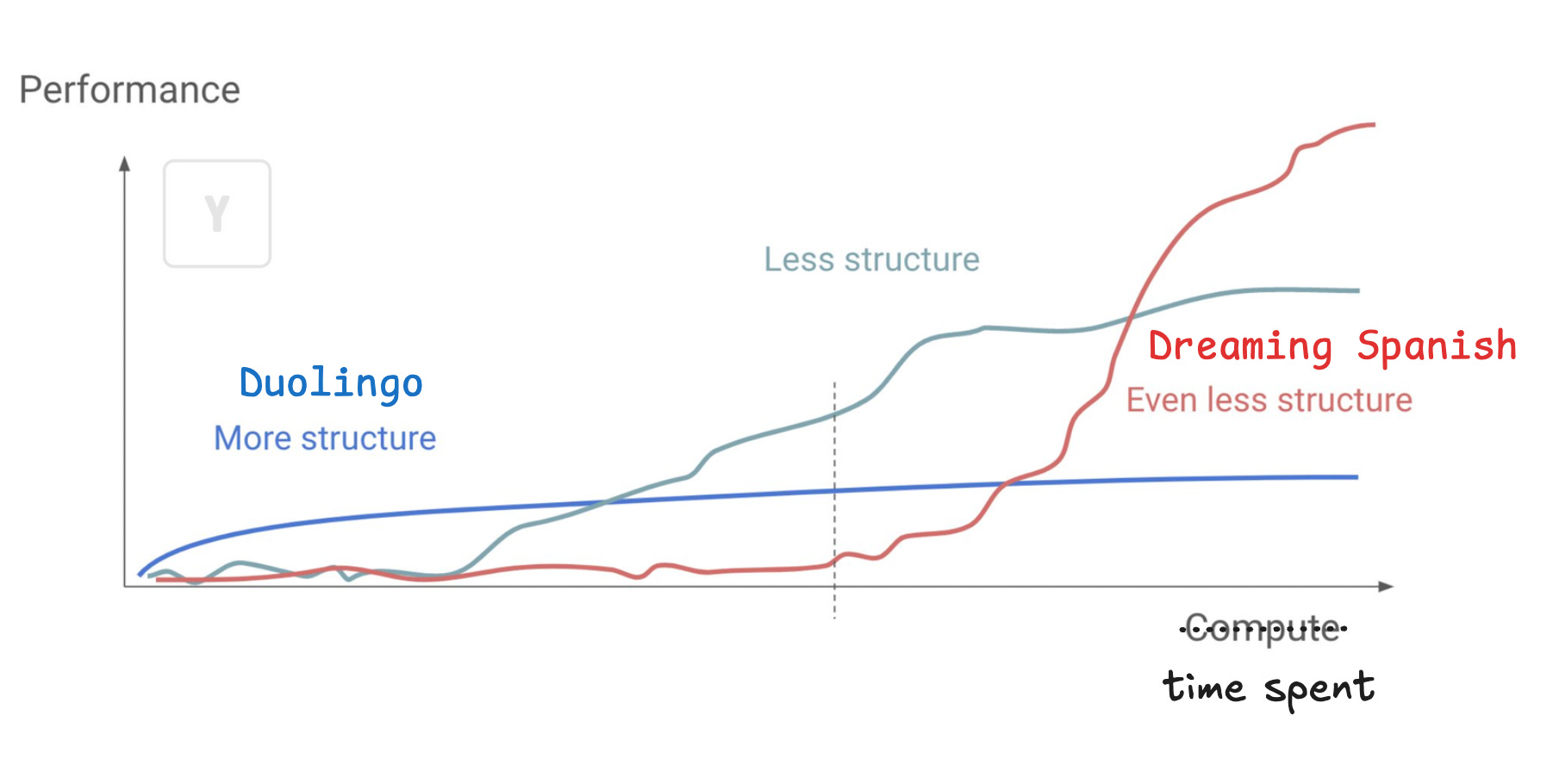
More interestingly, according to Dreaming Spanish, if you haven’t accumulated 600 hours of inputs, attempting to speak early will “invariably result in hard-to-fix non-native pronunciation, noticeably bad grammar, and poor word usage.” In other words, trying to interact and get environmental feedback without learning enough prior will lead to poor habits. This resembles one of the core insights from Shunyu’s blog post:
It turned out the most important part of RL might not even be the RL algorithm or environment, but the priors, which can be obtained in a way totally unrelated from RL. –– Shunyu Yao
All in all, this is to say that the paradigm of learning through next-token prediction has similar success in language learning. And comprehensive inputs (which is a lot of inputs + curriculum learning) makes you learn better, just like curriculum learning makes pretraining more efficient (Zhang et al., 2025).
This brings us to the next point.
you need immense inputs and interactive practice at the same time.
Dreaming Spanish’s curriculum also states that, for people with zero knowledge of the new language, "Listen A LOT. … (In addition,) Crosstalk is the most efficient activity that you can do, if you can find speakers of the language.” In fact, the combination of both listening a lot and crosstalking is encouraged till the learner becomes an intermediate speaker who can now speak the language.
Crosstalk is basically two speakers talking to each other in their own language. Like Person A speaking in English and the Person B speaking in Spanish on the same topic in multi-turn conversations. There’s no formal study behind why it is effective (aside from it engages the language learner) but the simple idea is that you get feedback from environment, especially at the later stage of learning.
The feedback might not be exactly explicit corrections or rewards, but rather sparse signals that emerge naturally from the interaction (e.g., a confused expression, a topic shift, a clarifying question, or simply whether the conversation flows or stalls.) Just like in RL where rewards can be delayed and indirect, in crosstalk you're learning from these sparse environmental cues about whether your comprehension and mental model of the language are on track, even without direct instruction or dense feedback on every utterance.
The point is, for language learners, it is best to combine both immersion (i.e., next token prediction) and interactions (i.e., RL). I will give another analogy.
learning a new language in a foreign country.
When you are in a foreign country picking up a new language, you’d do this throughout the whole day:
Listening on people around you talking. Reading signs or menus whose characters you don’t understand (but you make no efforts to understand them because you are overwhelmed.)
Pull up Google Translate to translate the words when you have to, such as when you are ordering food in a restaurant.
Awkwardly trying to crosstalk to people or using some vocab you learned from (2).
Now in machine learning terms in a high level sense, it would look like this:
Pretraining–level next token prediction: Listening and simply observing what you see. This is immersion (and maybe you might imitate).
Task-level next token prediction: You introduce a (translation) task for yourself to have to learn what the inputs mean and translate what you want to say.
RL: You try speaking, receive confused looks or incorrect orders, adjust based on whether communication worked or failed.
In fact, you will constantly do this 24/7 (except when you sleep) interchangeably, unlike current LLM training which follows a sequential approach.
so why aren’t we doing this blended, interleaved learning?
First of all, how would it look like?
We want to remove the structure of pretraining → RL and let the LLMs figure out how to combine and interplay both paradigms at scale.
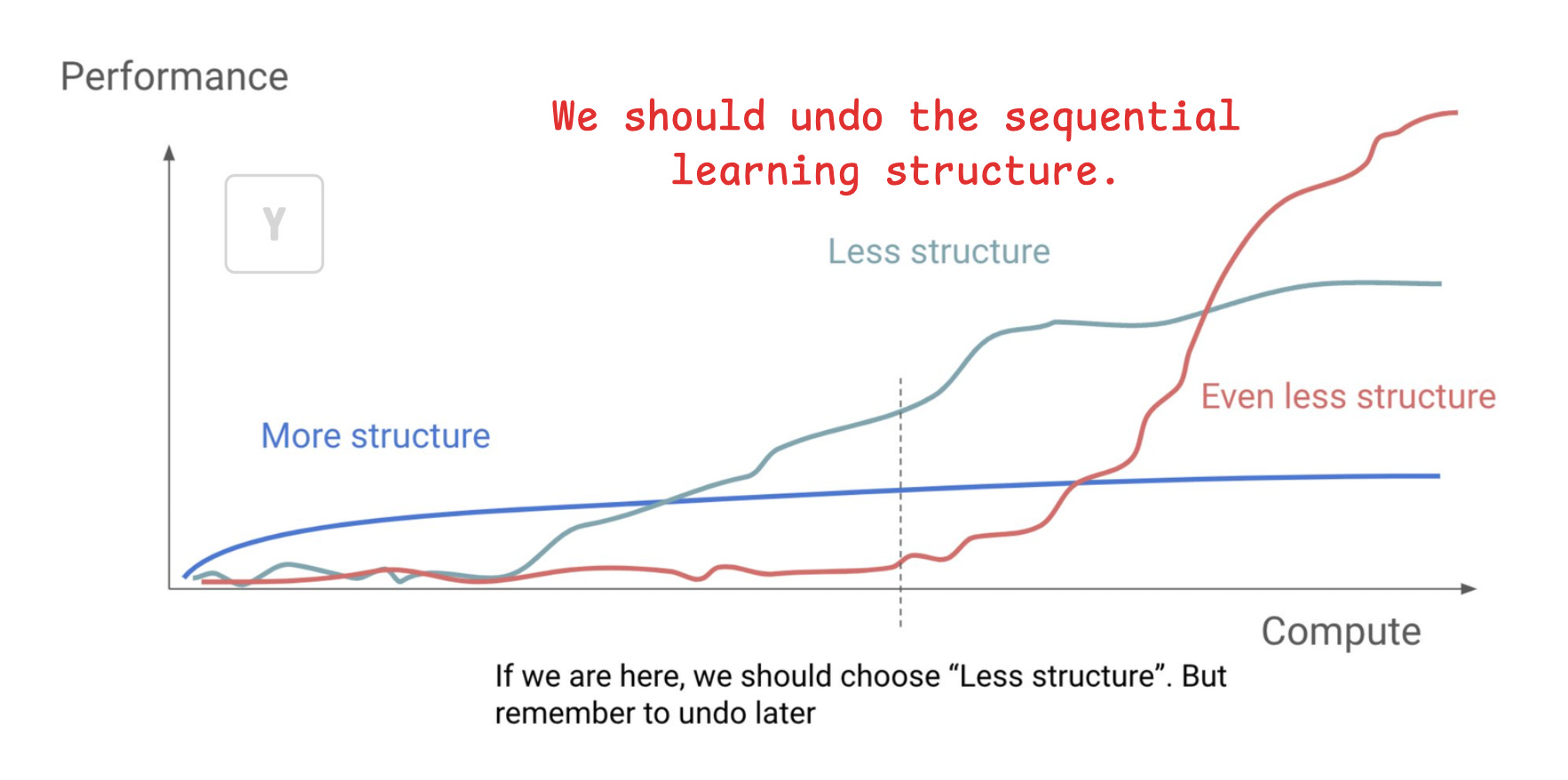
The high-level goal remains the same as how human combine passive and active learning in an unstructured form. That is, LLMs will passively learn patterns from large-scale corpora (with next-token prediction) while actively interacting with its environment to receive feedback and refine its behavior (like RL), and they figure out the curriculum to how to layer them and weigh the learning signals from both. It could take forms of continual learning loop with a new architecture that has alternating or hybrid heads where some parts specialize in prediction and others in control over RL interactions.
Interestingly, model merging work has shown signs of promise for this paradigm. For instance, interpolating RLHF and SFT model parameters can address alignment tax by adjusting the trade-off between human preference and basic capabilities (Lu et al., 2024). Here though, we aren’t just fixing tradeoffs but we want to shoot for the star with a totally new training paradigm.
Nonetheless, I could speculate a few reasons why this new paradigm might not work when scaled up:
compute efficiency: Pretraining on massive datasets first, then fine-tuning with RL, might simply be more compute-efficient than trying to do both simultaneously at scale.
environment: humans have embodied experience and multimodal input, but LLMs do not have such interactive multimodal environment that is readily available for such training. Also, RL-training data often has a very different distribution than internet text. Mixing these during training could lead to catastrophic forgetting or instability.
optimization difficulty: Simultaneously optimizing for both imitation (next-token prediction) and reward signals (RL) introduces interference.
credit assignment and learning objective: In blended settings, it’s harder to assign credit for improvements. How much weight to assign for passive next-token loss and reward signals?
But I don’t think they are fundamental limitations.
I believe that human learning is fluid, blending immersion with interaction, from the very start till the end. In contrast, LLMs are being trained in a hard-coded sequential pattern. If we want LLMs to become truly general learners like humans, we may need to move toward integrating both training paradigms from the ground up. Perhaps, this is also what David and Richard pointed to.
Agents will autonomously interact with environments through rich observations and actions. They will continue to adapt over the course of lifelong streams of experience.
David Silver, Richard S. Sutton* – “Welcome to the Era of Experience”
Appreciate Avi Trost for reading and suggesting Jack’s post (released yesterday like when I finished writing this yesterday independently as well) saying the exact same thing. People should read it as well.

Though I think there’s no need to do RL for pretraining. SFT is different from RL2, as SFT is more training efficient for pretraining corpora. Jack also said that “RL training really is teaching models something different” in his post.
Therefore, in my opinion, we should instead let LLMs do RL and SFT at the same time (where they weigh the ratio themselves) instead of us picking either:
RL for everything (Jack’s post, Reinforcement Pre-Training)
SFT for nearly everything (like pretraining → instruction-tuning/mid-training/RLHF → reasoning distillation such as s1 and OpenThought models) or
SFT → RL (current paradigm)
The two differences between pretraining and comprehensible inputs are that (1) the latter requires an environment so that you can follow what they are talking about. (2) the latter follows curriculum learning.
Theoretically, SFT can be derived from RL but in practice, simply learning the positive signals (what comes next) makes a different beast in learning from large corpora.